Prior to joining IDC, I used to work at a product and process innovation consulting firm. The technical staff – many of my colleagues – consisted of more than a hundred mechanical, electrical, chemical, and other engineers with multiple doctorate and post doctorate degrees. The company also actively maintained a network of scientists who played an advisory role and could be consulted on a moment’s notice. During my ten-year tenure this network grew into the thousands. The company’s top clients included Fortune 1000 companies – mostly in the manufacturing and consumer goods industries – with significant R&D investments.
This consulting firm was relatively small by most standards – chiefly a peer group of larger consulting firms – but that did not stop it from taking on some very cool assignments on behalf of its clients. It designed tiny antennas (a few millimeters tall) for the telecommunications industry, resolved vexing production problems with aluminum truck wheel manufacturing, solved corrosion issues with natural gas pipelines, lowered the cost of solar panels, developed new approaches for paint coatings, and even came up with a breakthrough dental whitening solution.
How could this firm be so effective in so many different disciplines? Because of a culture that fostered innovation. The company had developed a systematic innovation methodology that could be applied to any engineering, scientific, or research area. This methodology deconstructed an “engineering system”, whether it was a tooth whitening system or a truck wheel manufacturing system, into the functions between its underlying components. It determined which functions were useful and which were unnecessary, or even harmful, and then rebuilt the system by eliminating the unnecessary or harmful functions, and adding useful ones. For those of you in the know, this methodology was based on TRIZ – the Theory of Inventive Problem Solving. All kinds of other analytical tools were applied as well, that I won’t delve into here.
One could argue that this firm built “functional twins” of engineering systems that needed to be optimized, prototyped, or operationalized. This was long before terms like “digital twins” (used in the context of Operational Technology) were commonplace (A “Digital Twin” is a virtual representation and a real-time digital counterpart of a physical object or process). And indeed, no computers, except basic laptops, were involved in the analytical process used by the technologists at this firm. Simply put, the very reason that this small innovative consulting firm could thrive was because very few of its large clients had invested in, or could access, large high-performance computing (HPC) systems (such as the ones that could be found in research institutions and universities at the time), leave alone have in-house skills to codify or program pertinent problems onto these HPC clusters. You could say that this consulting firm’s core staff of 100 engineers and adjunct staff of 3,000 scientists represented parallelized human computers, a bit like the “human computers” that NASA employed for early Apollo missions, except decades later.
Today, companies can no longer rely on “human computers” for their R&D initiatives. Fierce competition, the constant quest to maintain or further an organization’s differentiation, and the need to make decisions steeped in digital information mean that almost every company – regardless of industry – must invest in high performance computing, artificial intelligence, and analytics infrastructure. And they must employ technical staff that can make effective use of these systems. We are in the era of what NVIDIA’s CEO Jensen Huang calls the “industrialization of HPC”. If data is the new oil, the industrialization of HPC is designed to make sure that the crude oil can be quickly extracted, refined, and made fit for consumption, internally and externally. What the firm I worked at delivered as a service, to clients that could afford it, will soon become table stakes for every firm in every industry, regardless of their size.
Revolutionizing Business Investments and Outcomes
The industrialization of HPC – also sometimes referred to as the democratization of HPC – is nothing more than HPC technologies becoming commonplace. Their adoption is no longer limited to well-funded national laboratories, universities, and select industries such as oil & gas, genomics, finance, aerospace, chemical, or pharmaceutical. HPC is gaining wider adoption in public and private research institutions, cloud, digital and communications service providers, and – crucially – at many enterprises. This is revolutionizing business investments and outcomes:
- Industrial firms are overhauling their manufacturing plants and R&D centers. Increased investments in software solutions enable scientists and technical staff to accelerate product and process innovation with precision and deterministic reliance.
- Fast, highly responsive, and disruptive, rather than incremental product and process innovation, are crucial for an organization’s competitiveness today, and such innovation is requiring increasingly more sophisticated approaches, including modeling and simulation on HPC systems.
- Companies are increasing their investments in artificial intelligence (AI), leading to a faster penetration of AI in enterprise workloads. IDC predicts that by 2025, a fifth of all worldwide computing infrastructure will be used for running AI. AI began on siloed systems in the datacenter but is increasingly being migrated to large clusters of the same type that can run HPC. Essentially these AI clusters are the benign Trojan horse that brings HPC clusters to the industrial world.
The growing availability of stupendous amount of computing at manageable costs (and measurable returns) – whether they are capital expenses for on-premises HPC systems or operational expenses for HPC as a service – has tremendous enabling power for scientists, engineers, and technical staff. Coupled with rich data sets, access to vast amounts of compute capacity has ushered in a new R&D culture among scientists. The ability to increase iterative runs without penalty allows them to tweak a model or run a simulation as often as necessary within acceptable timeframes.
This last point goes further than just the enabling of multiple runs. It also allows R&D in enterprises to take on a fundamentally scientific and data-led approach to their domain, one in which they are not just trying to develop solutions but are also starting to actively look for new problems (which can be solved using algorithmic approaches). Disruptive innovation lies in using technology to look for new problems, which is where scientific discovery usually begins.
HPC at IDC
All this brings me to why this is an important area for IDC and why I am fortunate to lead IDC’s reinvestment in this domain. IDC’s clients – which includes vendors, service providers, end users and financial investors – continue to seek high quality market research and intelligence on High Performance Computing. They have been calling on IDC to expand its global research framework to include HPC for a while now. And I am here to tell you that we heard you loud and clear. In other words, IDC’s coverage of HPC is born out of an unmet need in the market for reliable and actionable market data and insights, related trends, and crucially the convergence of HPC with emerging domains like Artificial Intelligence, Quantum Computing, and Accelerated Computing. In doing so, we want to ensure that any new HPC related coverage is taxonomically and ontologically aligned with IDC’s global industry research framework. This is a strategic investment area for IDC, and we plan to pursue it with all our might.
Starting January 2022 IDC is launching two HPC focused syndicated research programs (called continuous intelligence services or CIS). These programs (which will be part of my practice, and for which I am hiring two analysts – more on that below) will track the HPC market and industry from all aspects, including work done at national labs, universities, businesses, and other organizations across the globe. The two programs are:
- High-Performance Computing Trends and Strategies – this program will be our flagship HPC service covering industry and market trends, insights, end user adoption, use cases, and vendor strategies.
- High-Performance Computing as a Service – this program will provide insights into end-user adoption trends on High-Performance Computing as a service in dedicated, hosted and public cloud infrastructure.
Both programs will offer intelligence for vendors and service providers as they seek to offer technology stacks as a service to enable a variety of use cases related to High-Performance Computing
IDC has been following the HPC market closely for several years, using the term “Modeling and Simulation (M&S)”. We have examined M&S as a use case group that is spread across our enterprise workloads market segments and tied to the enterprise infrastructure markets that we track. Further, we define, track, size, forecast, and segment adjacent markets, technologies, and use case groups, namely:
- Infrastructure for Artificial Intelligence (AI)
- Infrastructure for Big data and Analytics (BDA)
- Accelerated servers used in AI, BDA, and M&S use cases
- Massively parallel computing (MPC) – IDC’s term for large scale parallel clusters
- Quantum Computing
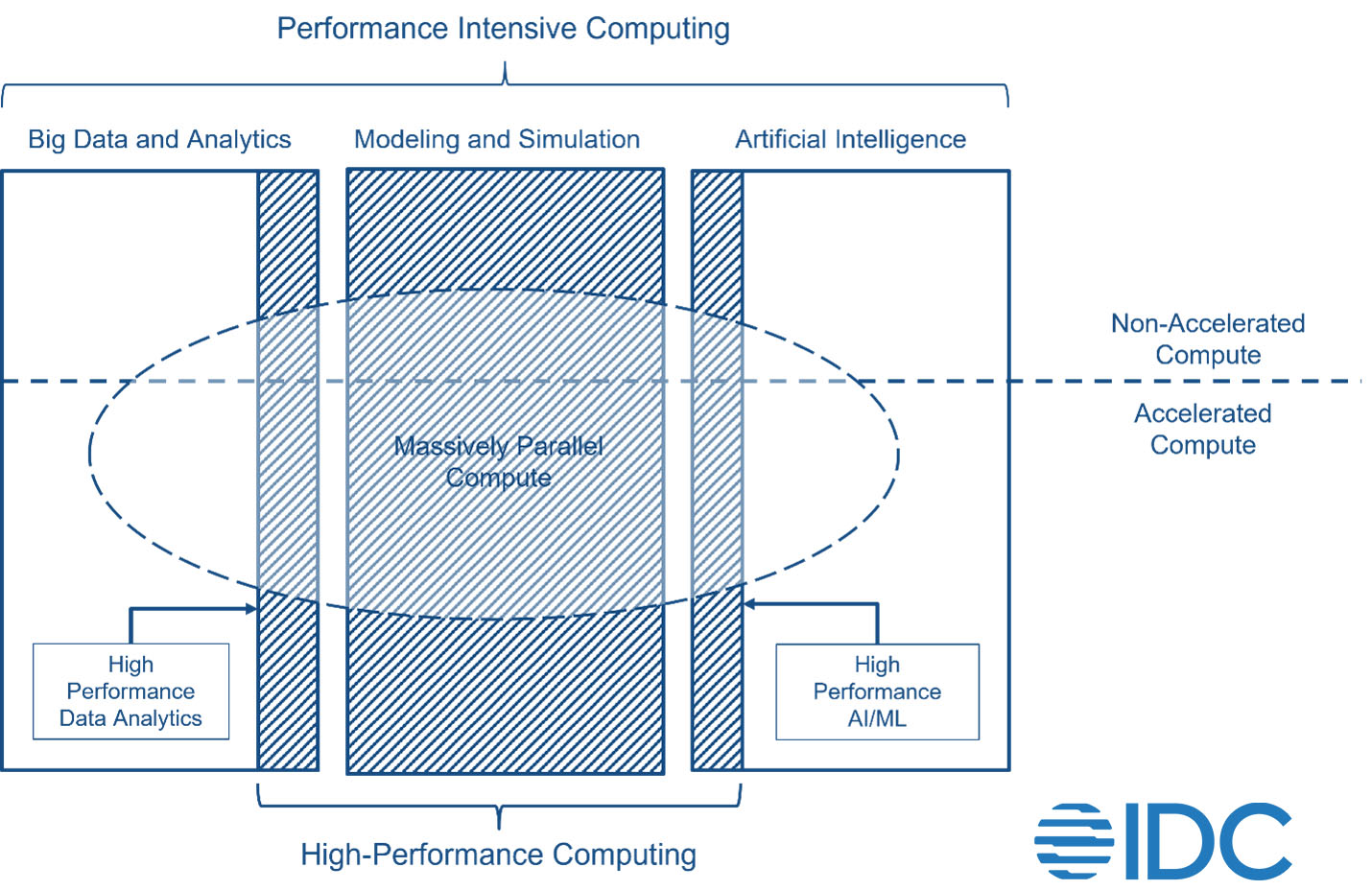
In doing so, we concluded that all of the above can be brought together under one umbrella term: Performance-Intensive Computing (PIC), notably because of a convergence of compute and storage infrastructure used for deploying workloads related to these use case groups.
IDC defines Performance Intensive Computing (PIC) as the process of performing large-scale mathematically intensive computations, commonly used in artificial intelligence (AI), modeling and simulation (M&S), and Big Data and analytics (BDA). PIC is also used for processing large volumes of data or executing complex instruction sets in the fastest way possible. PIC does not necessarily dictate specific computing and data management architecture, nor does it specify computational approaches. However, certain kinds of approaches, such as accelerated computing and massively parallel computing, have naturally gained prominence.
From the context of Performance Intensive Computing, IDC views HPC to be comprised of three principal market segments:
- Supercomputing sites that have been funded and custom-built for governments, national labs, and other public organizations
- Institutional or enterprise sites that have been built with a mix of custom and off-the-shelf designs
- Mainstream HPC environments that have been built with off-the-shelf designs to fulfill the technical and scientific computing needs of thousands of businesses around the world
When we define these markets, we make sure that they fit seamlessly together – like a puzzle. We also ensure that that they logically align to IDC’s definitions and tracking approaches for the worldwide enterprise infrastructure market. The figure below shows how, in IDC’s taxonomy, these markets fit together.
Ten years ago, firms such as the one I worked at prior to joining IDC used human experts to develop methodologies for solving or optimizing problems, by creating functional twins of engineering systems. Engineers would spend weeks taking a system apart (on paper), defining the functions between all the components, removing harmful or unnecessary functions, adding beneficial ones and then reconstructing the system with innovative new features. Today, engineering systems are recreated, analyzed, and optimized digitally, product and process innovation are performed with support from AI, HPC, and BDA, and scientists must have software development expertise. This shift is nothing less than a global digital transformation in the R&D and engineering departments at companies of all sizes. High-performance computing is now truly industrialized and is playing a central role in driving disruptive innovation.
And if you are interested in joining our new HPC practice, consider these fantastic job openings:
Should you invest in High Performance Computing solutions? IDC’s research and insights can be customized and designed around your specific product goals. Read our latest research on Performance-Intensive Computing Market Trends.
About the Author: Peter Rutten is Research Vice-President within IDC’s Worldwide Infrastructure Practice, covering research on computing platforms. Mr. Rutten is IDC’s global research lead on performance-intensive computing solutions and use cases. This includes research on High-Performance Computing (HPC), Artificial Intelligence (AI), and Big Data and Analytics (BDA) infrastructure and associated solution stacks.


